
AI
Z.ai Unveils GLM-4.5: A Breakthrough in Open-Source AI with Stellar Benchmark Performance
Revolutionizing AI Accessibility with Advanced Reasoning and Coding Capabilities
3 min read
By Timmy
Z.ai, a leading Chinese AI company formerly known as Zhipu, launched its latest flagship models, GLM-4.5 and GLM-4.5-Air, on July 28, 2025, marking a significant leap in open-source artificial intelligence. Designed to excel in reasoning, coding, and agentic tasks, these models have also demonstrated impressive results in a comprehensive benchmark evaluation released today, positioning Z.ai as a global contender in the AI race.
The GLM-4.5 series introduces a Mixture of Experts (MoE) architecture, with GLM-4.5 featuring 355 billion total parameters and 32 billion active parameters, and GLM-4.5-Air offering 106 billion total parameters and 12 billion active parameters. Both models unify advanced capabilities into a single framework, addressing the rising demand for complex agent-driven applications. Available on Z.ai, BigModel.cn, HuggingFace, and ModelScope under an open and auditable license, they support enterprise use cases with transparency and affordability, priced as low as $0.11 per million input tokens and $0.28 per million output tokens.
In a benchmark evaluation covering 12 tests—TAU-Bench, BFCL v3 (Full), BrowseComp, MMLU Pro, AIME 24, MATH 500, SciCode, GPQA, HLE, LiveCodeBench, SWE-Bench Verified, and Terminal-Bench—GLM-4.5 ranked third overall with a score of 63.2 out of 100, while GLM-4.5-Air placed sixth at 59.8. The data, provided by Z.ai, compares the models against top competitors from OpenAI, Anthropic, Google DeepMind, and others, including o3(65.0) and Claude 4 Opus (60.9).
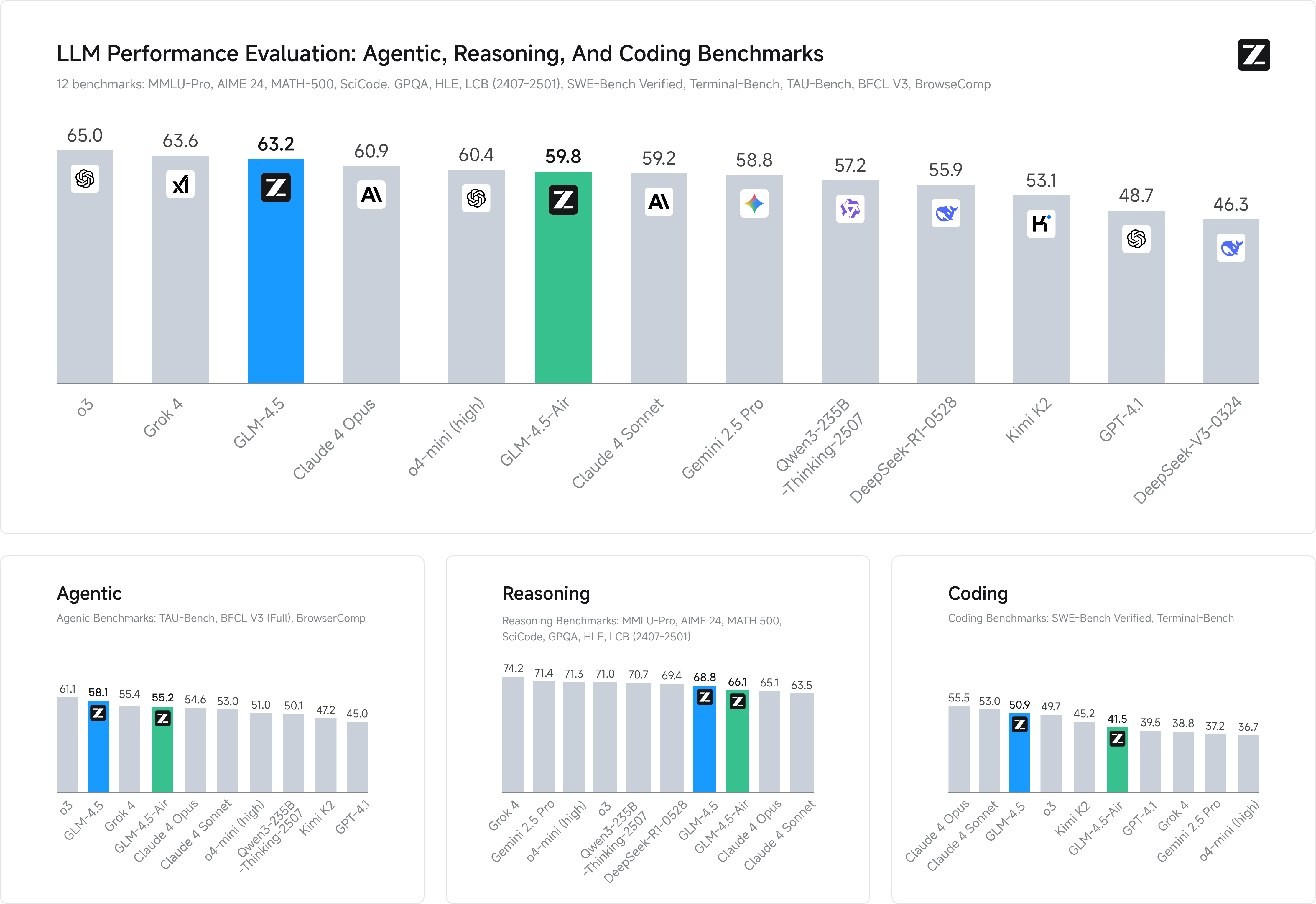
For agentic tasks, GLM-4.5 scored 58.1, outpacing Grok 4 (55.4) and achieving a standout 26.4% accuracy on BrowseComp’s web-browsing challenges—outperforming Claude-4-Opus (18.8%). GLM-4.5-Air followed closely at 55.2. In reasoning benchmarks like MMLU-Pro and AIME 2024, GLM-4.5 reached 68.8, trailing Qwen3-235B-Thinking-2507 (70.7) but surpassing Claude 4 Opus (65.1).In coding, GLM-4.5 posted 50.9 on SWE-bench Verified and Terminal-bench—behind Claude 4 Sonnet (55.5) yet ahead of GPT-4.1 (39.5)—highlighting competitive full-stack capabilities. The model also holds a 53.9 % win rate against Kimi K2 and an 80.8 % success rate over Qwen3-Coder across 52 coding tasks, along with a leading 90.6 % tool-calling success rate.
GLM-4.5’s agent-native design enables advanced planning, multi-step task management, and integration with coding toolkits like Claude Code and CodeGeex. It supports full-stack web development, presentation creation, and complex code generation, including interactive mini-games and physics simulations. Additionally, its high-speed version generates over 100 tokens per second, with pricing as low as $0.11 per million input tokens and $0.28 per million output tokens, making it a cost-effective solution.
As Z.ai advances its mission to create accessible, high-performance AI, GLM-4.5 sets a new standard for open-source models. Developers can explore its capabilities on Z.ai or through the BigModel.cn API, with model weights available for local deployment. This release challenges closed models like GPT-4, driving the global shift toward transparent AI development.



